

TAG:VLA模型

6万小时真实物理数据训练,蚂蚁灵波具身基座模型 LingBot-VLA 2.0 开源
蚂蚁灵波科技开源LingBot-VLA 2.0具身基座模型。该模型预训练融入6万小时高质量真实物理数据,覆盖17个主流机器人品牌、20种构型,全面支持头部、腰部、末端执行器及移动底盘自由度。在GM-100双臂操作评测和长程移动操作任务中以单一通用模型领先π0.5与GR00T N1.7,展现强大跨本体泛化能力。同时开源高效后训练版本(RTX 4090推理<130ms),已在零售、物流、工业场景启动商业落地测试。

中国团队用“会动的眼睛”破解VLA空间视觉难题:相机仅挪动几毫米,成功率就会暴跌一半
VLA模型对相机视角变化极度敏感,挪动几毫米成功率暴跌。中国狮子山人工智能实验室诊断出‘捷径学习’和三种隐性耦合,提出‘运动之眼’范式,让相机动态采集数据,使陌生视角成功率从43%提升至83%,性能提升26.8%,兼容主流VLA架构,论文IROS 2026收录。

具身智能空间视觉死穴被最新顶会彻底解决
VLA模型在机器人操作领域展现强大能力,但对相机视角变化极其脆弱,成功率可从90%暴跌至30%以下。狮子山人工智能实验室团队诊断出相机-基座、相机-物体、物体-位置三种隐性耦合导致的捷径学习问题,并提出以“运动之眼”移动视角为核心的混合动态数据采集策略,彻底打破虚假相关性,让模型真正学会空间几何关系。该论文已被IROS 2026接收,为具身智能从实验室走向真实世界提供关键突破。
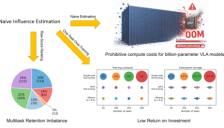
ATHENA将影响函数扩展到十亿参数VLA,实现313倍加速筛选高价值数据
具身智能进入数据Scaling时代,如何量化机器人示教轨迹价值成为关键。上海交大、同济大学等团队提出ATHENA框架,将影响函数扩展至十亿参数多任务VLA模型。通过Kronecker梯度压缩、随机截断加速Hessian逆和MII多任务交互机制,实现313倍加速(8054.6→25.7 GPU小时),从因果视角评估数据对下游任务成功率的影响。实验显示,筛选高价值数据后,模型用更少样本反而性能更优,为机器人数据curation提供可扩展新范式。

Generalist 摒弃 VLA 与世界模型,开辟具身智能原生交互新路径
硅谷具身智能独角兽Generalist跳出VLA与世界模型固化赛道,打造原生物理交互新路径。由DeepMind与波士顿动力核心团队创立,通过自研穿戴式采集设备积累50万小时真实人类交互数据,从零训练以力学反馈为核心的GEN模型,专注灵巧操作,验证物理AI缩放定律(成功率66%→99%),为具身智能商业落地提供第三条差异化路线。
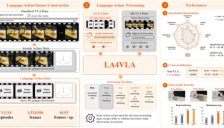
让机器人先学动作语言:LA4VLA 重新拆解 VLA 预训练
本文深入探讨了标准VLA模型中语言指令容易被视觉信息主导的问题,并通过实验展示模型在冲突情境下更依赖视觉而非语言。文章介绍了LA4VLA方法,它通过先进行无视觉的语言-动作预训练,让模型学习语言与动作的基本对应规律,再结合视觉进行完整策略学习,从而提升机器人对语言指令的真正理解与执行能力。

两家企业同日官宣,均自称为大湾区首个估值突破200亿元的具身智能企业
6月29日,深圳两家具身智能企业智平方与自变量机器人同日官宣估值均突破200亿元,均自称“大湾区首个”。两家2023年成立的公司在不到3年内通过密集融资实现高速增长,背后汇聚国家队与美团、阿里、字节、小米等巨头。双方均采用端到端VLA技术路线但侧重不同(NeuroVLA类脑模型 vs WALL世界统一模型),已在工业、家庭及C端场景实现落地,凸显赛道竞争白热化。
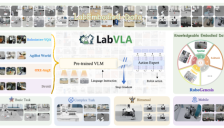
LabVLA:浙大与上海AI Lab联合探索科学具身智能,推动AI进入实验室
LabVLA项目由浙江大学和上海人工智能实验室联合推出,探索科学具身智能的新范式。通过引入视觉-语言-动作预训练模型,LabVLA使AI能够从自然语言实验描述中学习跨任务、跨环境的操作规律,利用知识增强的仿真数据引擎RoboGenesis和科学具身语料LabEmbodied-Data,在LabUtopia基准上实现高成功率并完成真机验证。这解决了现有实验室自动化系统泛化能力不足的问题,推动AI从认知推理向具身操作迈进,促进科学研究的实际应用。

SOTA刷新:具身模型ACE-Ego正式开源,解析机器人如何看懂人类动作
大晓机器人联合港中文发布并开源具身操作VLA模型ACE-Ego,在RoboCasa与RoboTwin两大基准刷新SOTA。文章解析其通过第一视角人类视频与机器人数据联合预训练的关键方案,以及在零售打包、装盒等复杂场景中的落地表现与泛化价值。

RSS 2026 | GuidedVLA:通过动作注意力专家化提升VLA模型对任务相关因素的可控可解释性
VLA模型动作解码器常成黑箱,易看错重点(如背景或伪相关)。GuidedVLA通过可控可解释的注意力专家分工(Object Head、Skill Head、Depth Head)显式指定任务相关因子,显著提升机器人抓取、放置等动作稳定性与可解释性。RSS 2026接收,代码开源。

具身机器人研究全都错了?最新论文:不能只靠VLA和世界模型
具身机器人研究的主流范式面临挑战。最新arXiv论文指出,仅靠更大的VLA模型和世界模型难以实现通用物理智能,当前研究存在机器人原生监督、弱监督视频和仿真模型的明显局限。论文提出缺失的四个核心组件(数据接口、具身接口、世界模型接口、奖励接口)及“具身自动标注”等未来方向,为构建真正可泛化的物理智能机器人提供新思路。
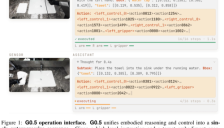
G0.5机器人开始实现边想边动
本文介绍了Galaxea G0.5技术报告中的新型Vision-Language-Action模型,该模型通过自回归方式将视觉理解、语言指令、推理规划和动作生成统一在一个序列中,实现机器人'边想边动'的智能控制。它创新性地解决了动作token爆炸问题,支持跨机器人泛化,提升了实时性和任务执行效率,为机器人智能发展提供了新方向。

首次纯人类视频预训练VLA实现灵巧操作,少量数据微调即可部署成功
该研究首次提出使用纯人类视频预训练视觉-语言-动作(VLA)模型,实现机器人灵巧操作。通过VITRA框架,自动从人类活动视频中提取3D手部运动轨迹、分割原子动作并生成语言指令,构建了超大规模数据集。预训练模型展现出强大的零样本手部动作预测能力,仅需少量真实机器人数据微调,即可在真实环境中高效部署,对新物体和环境泛化能力强,显著降低了机器人学习的数据获取成本。

小鹏第三次参加CVPR:自动驾驶下一步,并非VLA与世界模型二选一
小鹏汽车在CVPR 2026上第三次登台,分享自动驾驶技术的新方向。文章核心指出,自动驾驶的下一步不是VLA与世界模型二选一,而是两者融合互补。小鹏的第二代VLA模型已实现量产,用户辅助驾驶里程占比突破50%,同时世界模型通过“向世界学习”来增强物理理解,共同构建深度理解真实世界并安全行动的架构。这展示了小鹏在工程落地和技术创新上的领先地位,推动自动驾驶规模化应用。

HiF-VLA推出以motion为中心的边想边做世界动作模型
本文介绍了HiF-VLA,一个以运动为中心的双向时空推理框架,旨在解决视觉-语言-动作模型在长程任务中的因果混淆问题。通过提取低维Motion向量替代冗余图像输入,该框架实现了高效的时间建模,使机器人能够‘边想边做’,理解物理世界动态。在CALVIN等评测中,HiF-VLA显著超越现有方法,为构建世界动作模型开辟了新路径。







