

TAG:MoE架构
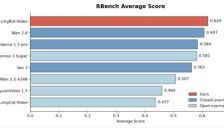
蚂蚁灵波开源 LingBot-Video,发布全球首个面向具身智能的视频基础模型
蚂蚁灵波开源LingBot-Video,这是全球首个基于MoE架构、面向具身智能的开源视频生成基础模型。该模型在RBench基准上以0.620总分超越Wan2.6等,通过DiT+MoE(30B仅激活3B,3倍效率)、7万小时具身数据及物理合理性与任务完成度强化学习,在物理规律、动作一致性和任务执行上实现突破,为机器人动作预测、仿真数据生成、世界模型研究提供全新开源底座。

腾讯 Hy3 编程评测结果出炉:参数量仅为对手五分之一,代码能力与 DeepSeek-V4-Pro 持平
腾讯Hy3编程评测出炉:这款MoE架构的混元最强模型,总参数295B但激活参数仅21B,仅为DeepSeek-V4-Pro等对手的五分之一,却在SuperCLUE真实编程场景专项测评中取得47.37分,与其完全持平。测评针对国内程序员多轮迭代开发流程,在成本(单题0.43元)、速度(<400秒)、沟通轮次(约40轮)和Token消耗上优势显著,展现极高性价比。该模型已Apache 2.0协议全面开源,证明优化架构可让“小身材”实现“大能量”,为开发者提供性能与成本完美平衡的AI编程利器。
腾讯混元Hy3发布:Agent能力和产品体验显著提升
7月6日,腾讯混元Hy3正式发布。该模型采用MoE架构,总参数295B、激活参数21B,支持256K上下文。相比preview版本,在复杂推理、指令遵循、代码生成和Agent能力上实现全面跃升,智能水平比肩2-5倍参数的旗舰模型。已在WorkBuddy、元宝、Marvis、ima等业务深度接入,WorkBuddy任务成功率从72%提升至90%,幻觉率下降超50%,内部盲测优于GLM5.1。API已在腾讯云TokenHub上线,定价降低、性价比大幅提升,为办公生产力和智能体应用带来实用性质变。
腾讯发布混元3.0大模型,编程能力大幅提升
腾讯近日推出新一代AI大模型混元3.0(Hy3),核心编程能力实现飞跃,在SWE-Bench测试中性能提升超40%。该模型采用MoE架构,具备262K长上下文处理能力及高效推理速度,性能逼近国内顶尖水平。混元3.0的发布标志着腾讯在AI研发上的重大突破,为开发者提供了更强力的工具,进一步加剧了大模型市场的竞争。

国产大模型Qwen3.6-35B-A3B正式开源,聚焦高效率与多模态思考能力提升
国产大模型Qwen3.6-35B-A3B正式开源,该模型采用创新的MoE架构,实现350亿总参数下仅需激活30亿参数的极致推理效率。其在编程、Agent任务及多模态思考方面表现优异,尤其在空间分析和复杂逻辑处理上极具优势,且已深度兼容主流Agent框架,是开发者本地部署高性能AI底座的理想选择。

腾讯混元2.0内测启动,406B参数号称推理性能国内领先
腾讯发布新一代自研大模型混元2.0,总参数达406B,采用MoE架构提升推理速度,在数学、代码等复杂任务上表现突出,支持256K长上下文窗口。模型已在腾讯云API及元宝、ima等应用灰度上线,并计划于2026年开源,推动国产大模型生态发展。

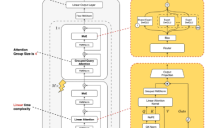
蚂蚁百灵大模型团队开源Ring-flash-linear-2.0-128K,混合注意力+MoE架构重塑长文本编程效率
蚂蚁百灵大模型团队开源Ring-flash-linear-2.0-128K,采用混合线性注意力机制和MoE稀疏架构,仅激活6.1B参数即可媲美40B密集模型性能。该模型原生支持128K上下文窗口,可扩展至512K,在代码生成和长文本编程任务中实现SOTA表现,推理速度提升3倍以上,为开发者提供高效AI编程解决方案。







