

TAG:MoE

阿里黑科技炸场!0.6B 小模型“魔改”成 17B MoE,激活参数仅 5%,CPU 直接跑 30token/s!
本文介绍阿里国际数字商业团队推出的Marco-Mini-Instruct MoE模型,该模型通过Upcycling技术由0.6B小模型升级为17B总参数规模,激活参数仅5%,CPU上可实现30token/s的推理速度,性能超越4B级Dense模型,为行业提供了低成本、高效率的MoE炼制新路径,大幅降低中小团队落地MoE的门槛。
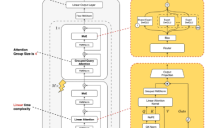
蚂蚁开源Ring-flash-linear-2.0-128K模型,混合注意力与MoE架构提升长文本编程效率
在AI大模型竞争白热化的当下,高效推理与长上下文处理已成为开发者痛点。近日,蚂蚁集团旗下百灵大模型团队正式开源Ring-flash-linear-2.0-128K,一款专为超长文本编程设计的创新模型。

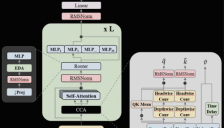
AI算力的“B计划”:当AMD与IBM联手,用1024张MI300X,炼出了第一个“非NVIDIA”大模型
AMD携手IBM与Zyphra发布全球首个纯AMD硬件训练的大模型ZAYA1,采用MoE架构预训练14T tokens,性能与Qwen3系列持平。ZAYA1创新性采用CCA注意力机制和线性路由MoE,在数学推理等STEM领域表现优异,验证了AMD MI300X+ROCm在大规模模型训练中的可行性。





美股三大指数震荡整理,芯片股走高,光通信板块大涨
2026-05-11
0 浏览
多空胶着恒指震荡整理,AI景气外溢主导行情波动
2026-05-11
0 浏览
宠物AI公司PurrPurr获阿尔法公社投资 首年GMV目标5000万
2026-05-11
0 浏览
隆源股份业绩说明会回应今年新能源汽车零部件领域新客户洽谈中
2026-05-11
0 浏览
中国品牌市占率达75%,4月我国汽车销量约252.6万辆,新能源汽车出口贡献度近五成
2026-05-11
0 浏览
4月汽车出口增长51% 国内零售下跌超20%
2026-05-11
0 浏览
4月全国新能源汽车渗透率历史首次突破60%,燃油车零售同比暴跌37%
2026-05-11
0 浏览
港股复盘:强势翻红 芯片概念股冲高回落 短期风险需警惕
2026-05-11
0 浏览
申昊科技拟设具身智能子公司 加码人形机器人业务
2026-05-11
0 浏览


