

TAG:Deepseek
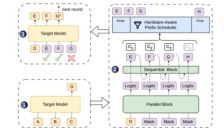
北大与DeepSeek联合开源大模型推理框架DSpark,实现算力提速关键突破
北京大学与DeepSeek联合开源DSpark大模型推理加速框架。该框架针对高并发自回归生成中的响应延迟与算力浪费痛点,创新采用半自回归架构(2层Transformer优于5层并行模型)与置信度调度验证机制。在代码、数学、对话等多场景测试中显著优于Eagle3和DFlash,尤其擅长长序列生成。已落地DeepSeek-V4服务并全面开源代码、权重及工具,为行业提供低成本高性能推理技术范式。

DeepSeek发表重磅论文,提出两项互补机制,大模型推理最高提速85%
DeepSeek联合北大提出DSpark推测解码框架,通过半自回归生成架构与置信度调度验证两项互补机制,实现大模型推理速度提升60%-85%。该技术已部署于V4系列及Qwen、Gemma等主流模型,配套开源DeepSpec全栈代码库,有效降低中小企业大模型落地门槛。

DeepSeek加码Harness人才布局,AI发展路径由轻转重
DeepSeek近期通过招聘Harness人才,加大对Agent领域的投入,标志着其AI发展路径可能由轻资产模式转向重资产策略。文章分析了Harness在AI生态中的关键作用,以及DeepSeek通过510亿元融资布局产业协同,探讨了未来发展方向和行业趋势。

AI领域成本压力下,微软Copilot拟引入DeepSeek模型
微软Copilot Cowork进入商用阶段后,面对高昂的模型调用成本压力,正计划引入中国的DeepSeek V4模型作为低成本选项。这一举措若落地,将标志着美国大型科技公司首次在核心企业级AI产品中采用中国大模型,反映了AI行业在竞争加剧下通过开放、灵活的模型策略来优化成本和提升效率的趋势。微软通过模型分层路由机制平衡算力与服务质量,寻求可持续增长路径。

DeepSeek完成A轮融资510亿元,腾讯京东等巨头参与
国内领先的开源大模型研发商DeepSeek宣布完成A轮融资,融资金额高达510亿元人民币,估值飙升至4000亿元。投资方阵容豪华,包括腾讯、京东、网易等互联网巨头及宁德时代,竞争激烈到由公司筛选准入资格。DeepSeek成立于2023年,专注于大语言模型和多模态AI技术,是开源大模型领域的领头羊。母公司幻方量化背景深厚,此次巨额融资将加速其在通用人工智能基础技术领域的研发与创新。

大厂难以承受AI巨额成本 微软智能体考虑换用幻方DeepSeek
微软因AI模型成本高昂,正考虑引入中国DeepSeek模型作为低成本替代方案。文章指出,微软Copilot Cowork智能体的高调用费用让企业难以承受,而DeepSeek模型价格仅为西方模型的五分之一。微软计划在Azure云上托管此方案,预计几周内推出,为企业提供更经济高效的智能化转型选择。

DeepSeek完成逾70亿美元首轮融资,估值超500亿美元
AI大模型独角兽DeepSeek完成首轮逾70亿美元融资,投后估值突破500亿美元。此轮融资采用创新架构,资金由CEO梁文锋管理的有限合伙企业持有,投资者享有五年锁定期但无表决权,保障创始人绝对控制权。梁文锋个人出资200亿元,腾讯和宁德时代作为主要外部投资者参与。此巨额融资为DeepSeek在AI竞争白热化的市场中提供资金储备,并树立了平衡资本引进与治理独立性的行业新范式。

DeepSeek 拟采用蜜雪冰城打法 打造中国版 Claude Code
DeepSeek 通过永久降价 V4‑Pro API,将输入缓存成本降至 0.025 元/百万 token,输出降至 6 元,并提供 500 并发,显著提升性价比,为开发者和企业提供更具竞争力的 AI 接口。

DeepSeek大消息引发AI基建全线飙涨799%
本文报道了AI基建领域的市场爆发和未来前景,包括N高特公司上市首日股价飙升799%,以及DeepSeek招聘IDC设计规划工程师,可能自建GW级数据中心。同时,分析指出AI基建已成为高景气度投资赛道,相关板块全线爆发,行业预计将进入数万亿美元的超级建设周期,展现出强劲的成长潜力和防御性投资价值。

中国AI大模型调用量连续6周领跑 全球前5占4席 DeepSeek稳居第1 Claude跌出前5
根据OpenRouter最新数据,上周全球AI大模型总调用量达36.1万亿Token,连续七周上涨。其中,中国AI大模型调用量为14.19万亿Token,环比增长27.49%,连续六周领跑全球,前五名中占据四席,DeepSeek-V4-Flash稳居榜首。同时,Claude系列模型双双跌出前五,显示出中国模型在高性价比、快速迭代和开发者生态中的优势,反映了全球市场格局的变化。

GPT 5.5 在 AI 漏洞挑战中领先,DeepSeek 获得性价比之王称号
安全研究员通过构建故意留有漏洞的图书评论应用,测试多款大语言模型的安全推理能力。在2小时和10美元预算限制下,GPT-5.5以70%的成功率领先,但成本高达9.46美元/次;而DeepSeek V4 Pro虽成功率较低,但成本仅0.62美元/次,展现出极高的性价比。文章突出了模型在漏洞识别中的性能对比与成本权衡。

DeepSeek被曝开启中国AI最大规模融资 估值4000亿腾讯与宁德时代入局
DeepSeek被曝启动中国AI史上最大规模融资,计划募资500亿元人民币,估值高达4000亿元。腾讯和宁德时代等巨头分别出资100亿元和50亿元入局,创始人梁文锋个人出资200亿元以保持公司控制权。这轮融资反映了AI行业竞争白热化,产业资本加速布局,有望推动DeepSeek技术优势转化为商业价值,改写大模型竞争格局。

腾讯、宁德时代拟巨额参投,DeepSeek首轮融资估值或达4000亿元
中国AI初创企业DeepSeek进行首轮巨额融资,计划筹集500亿元人民币,估值预计达3500亿至4000亿元。腾讯和宁德时代分别考虑投资100亿和50亿元,成为主要外部投资方。此次融资凸显了中国AI产业从模型研发到能源基础设施的全链路自给自足趋势,腾讯借此追赶竞争对手,宁德时代切入AI数据中心,有望刷新大模型估值纪录并重塑AI赛道战略同盟。

腾讯云大模型全面降价,最高降幅达97.5%,与官方原厂价持平
腾讯云智能体开发平台宣布自6月3日起对DeepSeek V4系列大模型进行大幅降价,最高降幅达97.5%。主力模型DeepSeek-V4-Pro推理价格降75%,缓存命中价格降97.5%;DeepSeek-V4-Flash缓存降90%。此举旨在降低企业与开发者AI应用成本,推动创新,并与DeepSeek官方降价持平,加剧云计算市场竞争,促进AI技术普及。

DeepSeek V4降价75%并保留永久折扣,登顶全球AI性价比榜首
DeepSeek公司近日宣布其旗舰AI模型DeepSeek-V4-Pro永久降价75%,将限时优惠转为永久定价。这一举措使其在权威评估中登顶全球AI性价比榜首,成本仅为OpenAI GPT-5.5的十二分之一。同时,模型性能保持世界前沿,智能体和代码构建能力突出,展示了高性价比与顶尖技术的结合,引领AI普惠风暴。







