

TAG:AI训练
字节跳动申请“刀盾狗”“草地牛”等表情包著作权,这些表情包还能使用吗?
字节跳动申请“刀盾狗”“草地牛”“香蕉猫”等热门网络表情包著作权登上热搜。律师解读:登记合法但不独占,个人非商业使用如聊天、朋友圈玩梗属于合理使用范畴,不构成侵权。该事件或与AI训练相关,解答网友对表情包使用规则的疑问。
谷歌隐私设置静默更新:你的数据正在喂养AI,如何守护个人信息
谷歌悄然更新隐私政策,默认将用户上传的图片、视频、音频等媒体数据用于AI模型训练,涵盖搜索、地图、翻译等多项服务。本文详解这一变化的影响,并提供关闭“保存媒体”选项及设置数据自动删除周期的实用方法,帮助用户在AI时代有效守护个人信息。

谷歌强推AI训练新规,要求数据提供否则面临限制
谷歌近期向新闻出版商发出通知,要求授权其内容用于AI训练,否则将终止合作并停止支付年费。此举在媒体行业引发强烈不满,涉及平台霸权主义和版权争议。同时,全球监管机构如欧盟已启动反垄断调查,传统媒体也对AI巨头发起版权诉讼,突显科技巨头与内容创作者之间的权益博弈。
Meta监控员工AI训练两个月后泄露4.5万张隐私数据表 1600人联名呼吁停止
Meta启动'模型能力计划'项目,通过监控员工行为训练AI,但两个月后因配置错误导致约4.5万张隐私数据表泄露,涉及员工私人对话、税务和医疗信息。1600多名员工联名请愿要求停止,事件暴露了AI训练中的隐私风险、数据安全漏洞,并可能违反GDPR等法规,为行业敲响警钟。

AI训练边界再引争议:Meta因数据安全事故叫停内部员工监控计划
Meta公司因内部数据泄露事故紧急暂停了‘模型能力计划’AI训练项目,该项目通过监控员工键盘和鼠标数据来训练模型。事件导致敏感信息外露,引发隐私担忧,再次将AI训练中的数据边界、安全合规与员工隐私平衡问题推向行业焦点。

Meta缩减监控员工训练AI计划 员工反弹与技术问题
Meta公司内部AI训练计划通过追踪员工键盘和鼠标数据来训练AI,但引发超千名员工强烈反对,认为监控侵犯隐私,加剧信任危机。在联名请愿和技术故障的双重压力下,Meta被迫缩减计划,允许员工暂停监控并豁免敏感职位。事件凸显了企业在AI部署中平衡数据需求与员工隐私的困境,反映了科技巨头面临的内部信任挑战。

xAI被指利用Claude输出数据训练编码模型,因Anthropic撤销权限转而秘密提取
xAI被曝利用Anthropic的Claude模型输出数据训练自身的Grok编码模型,即使在Anthropic于2026年1月撤销API权限后,仍通过个人账户及第三方服务Blackbox AI进行非官方数据提取。事件揭示了AI行业在高质量训练数据枯竭背景下的普遍焦虑,以及xAI内部预训练团队缩减、多名核心成员离职和重大工作失误的困境,预示着单纯依赖外部数据的模式正遭遇瓶颈,企业需在自主创新和组织稳定性上寻求突破。

马斯克旗下xAI全球招募中文AI训练师 时薪最高304元支持远程兼职
马斯克旗下xAI近日全球招募中文AI训练师,负责训练及优化大模型Grok的多语言语音互动能力。该职位时薪高达304元,支持远程兼职工作,每周仅需至少10小时,工作灵活自由。要求应聘者具备中文母语水平和英语B2以上能力,有语言学或音频标注等相关经验者优先。这是一个高薪、灵活的远程工作机会,适合语言技能突出的人士。

xAI面向全球悬赏“最懂中文的声音”,时薪达304元支持远程
xAI公司于2026年6月公开招募中文AI训练师,时薪高达304元并支持远程工作,旨在优化其大模型Grok的语音互动和多语言处理能力。该岗位涉及语音标注、录音和转写,要求候选人具备中文母语水平及口音理解,以在AI多模态竞争中构建技术优势,标志着AI向实时交互的演进。

全球100强、中国66强 人形机器人实力榜发布
摩根士丹利最新报告《Humanoid Horizons: Money Meets Machines》发布人形机器人全球100强和中国66强榜单,揭示了中美在产业链中的主导地位。报告指出,行业正从技术演示转向长期稳定工作能力,游戏世界成为机器人训练新场域,规模化制造能力成为竞争关键,为投资者和从业者提供了重要产业洞察。

京东机器人数采中心实探:宝妈工人参与擦桌缝纫日常助力AI物理世界应用
本文实地探访了京东在宿迁的具身智能数据采集中心,揭示了宝妈、工人等普通人群如何通过头戴设备采集擦桌、缝纫等日常动作数据。这些数据经过清洗和标注后,用于训练AI模型,帮助机器人更好地理解和适应物理世界。文章强调了多场景数据采集对提升模型泛化能力的重要性,以及京东计划在两年内积累超1000万小时数据,以推动具身智能技术的产业化进程。
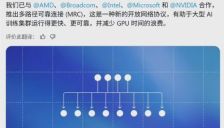
OpenAI 联合英伟达等巨头发布 MRC 协议,重塑大规模 AI 训练网络架构
OpenAI联合AMD、博通、英特尔、微软和英伟达等巨头,共同推出多路径可靠连接(MRC)协议,旨在解决大规模AI训练中的网络延迟和故障问题。该协议通过多平面网络设计和自适应数据包喷淋技术,将传统三层架构简化为两层,显著减少组件数量和能耗,实现微秒级故障自愈。MRC协议已在英伟达超级计算机和甲骨文云中应用,标志着AI基础设施向更高效、坚韧的架构转型。

多出版商控告 Meta:AI 训练或涉嫌侵权
近日,Meta因涉嫌侵犯版权面临多家知名出版商的集体诉讼,指控其未经许可使用书籍和期刊文章训练AI模型Llama。Meta回应称,使用版权材料训练AI可能构成合理使用,并将积极应诉。这起诉讼凸显了科技与版权之间的紧张关系,可能对未来AI训练方式产生深远影响。
国内7家主流财经媒体发布版权保护声明:禁止AI未经许可抓取原创内容
4月27日,7家主流财经媒体同步发布或更新版权声明,明确禁止任何机构和个人未经授权将其原创内容用于AI训练、机器学习和数据挖掘。此举标志传统内容方主动参与AI时代规则制定,旨在维护原创价值、强化版权边界,并推动内容生产者获得合理尊重与商业回报。

数据成具身智能最大短板,赛道打响数据争夺战
文章聚焦具身智能行业的核心瓶颈——高质量数据稀缺。随着资本升温,企业从“拼算法硬件”转向“拼数据基建”,觅蜂、京东、戴盟、百度等相继布局采集、标注、训练与交易平台。文中指出,真正决定竞争力的并非数据总量,而是高价值数据提炼及“数据-模型-数据”闭环迭代能力。







