

TAG:AI图像生成
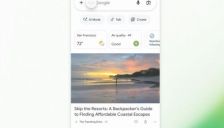
谷歌搜索引入“无结果生图”功能:AI概览变身创意画布,或进一步分流网站流量
谷歌正将AI图像生成功能无缝融入“AI概览”,用户输入提示即可快速生成图像,基于Nano Banana2Lite模型。未来该功能将逐步在支持AI图像生成的地区上线,引发外界担忧:AI直接生成内容或进一步分流传统图像搜索带来的开放网络流量。同时,谷歌图片首页也将推出动态个性化推荐功能,让用户收藏和发现更便捷。
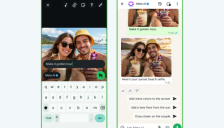
上线仅三天,Meta因强烈隐私抗议删除图片AI功能
文章围绕Meta原生AI生图工具Muse Image上线三天即下线事件,分析其通过@账号调用公开内容生成图片所引发的隐私同意、肖像权、版权及深度伪造争议,并对比国内外社交平台在AI能力开放与治理上的不同策略。
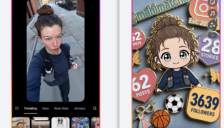
Meta新AI图像功能因争议下线
Meta本周推出的AI图像生成模型Muse Image在Instagram上线后迅速引发舆论危机。该功能允许用户引用公开账号一键生成AI图像,且默认开启,被指严重侵犯肖像权。美国演员工会SAG-AFTRA及反性剥削中心强烈批评,认为默认opt-out机制不可接受,可能助长性勒索等犯罪。面对广泛指责,Meta最终将该功能彻底下线。本文揭示了AI快速发展中的隐私伦理挑战。

字节跳动发布 Seedream 5.0 Pro,开启交互式精准编辑新时代
字节跳动正式发布Seedream 5.0 Pro多模态图像创作模型,标志着AI图像创作从“生成”迈向“设计”新高度。该模型在复杂信息可视化、交互式精准编辑(支持点选圈选、草图渲染、材质替换)、真实影像质感及原生多语种支持四大核心能力上实现突破,已上线火山方舟体验中心,并将登陆豆包与即梦平台,为专业设计师和创作者提供高效、可控的高质量创作工具。

Meta超级智能实验室发布首款图像模型Muse Image:支持对话生成,Instagram和WhatsApp可免费使用
Meta超级智能实验室首发图像生成模型Muse Image,支持通过对话在Meta AI、Instagram和WhatsApp免费生成高质量图像。该模型不仅能文生图,还支持擦除路人、渲染文字、AI重装房间等实用功能,并搭配Muse Spark提供智能规划和30+Instagram Stories特效。Muse Video视频模型也已在开发中。

Meta在聊天机器人和Instagram推出AI图像生成模型
Meta Platforms推出名为Muse Image的全新AI图像生成模型,这是该公司在首席AI官Alexandr Wang领导下重建AI实验室后的首次发布。该模型将嵌入Instagram、WhatsApp等社交应用中。同时,Muse Video也将很快面向创作者与Meta AI开放。

谷歌发布 Nano Banana 2 Lite 模型 图像生成再提速 性价比挑战行业门槛
谷歌正式发布Nano Banana 2 Lite新一代AI图像生成模型,单图生成速度压缩至4秒以内,每1000张图像成本仅0.034美元(约0.23元人民币)。该模型已在Google AI Studio、Gemini API等多平台全面上线,较前代实现速度与性价比双突破,为创作者和企业提供高效、低成本的视觉内容生产工具,加速生成式AI向实时普及方向发展。

今日起,全美谷歌Gemini免费用户均可使用个性化AI生图功能
谷歌宣布,即日起全美Gemini免费用户正式开放个性化AI图像生成功能。此前仅限付费用户的进阶体验现已下沉。Gemini通过整合用户授权的Gmail、谷歌相册、YouTube及搜索数据,智能理解个人兴趣偏好。只需简洁指令即可生成高度贴合的图像,支持直接调用相册内容,并提供灵活隐私控制选项。这一升级标志着AI个性化时代加速到来,Gemini月活用户已超7.5亿,未来还将推出AI视频生成和个人AI智能体等功能。
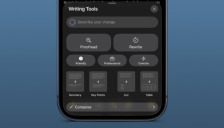
苹果AI迎来重大强化 Image Playground将在OS27中实现大幅提升
苹果的Image Playground AI功能在OS27系统中将迎来史诗级强化。通过升级的Apple Foundation模型和集成谷歌Gemini处理器,图像生成能力将大幅提升,摆脱以往表现不佳的困境。该功能将深度嵌入备忘录等系统应用,并增强Genmoji的主动性。苹果坚守隐私安全底线,拒绝深度伪造,确保本地或私有云处理,同时引入第三方模型API,为用户更多选择,但提醒隐私风险。这标志着苹果AI在实用性和道德标准上的重要进步。

谷歌发布全新Google Pics应用,AI助力图像设计与编辑
谷歌在2026年I/O开发者大会上发布了全新的Google Pics应用,这是一款AI驱动的图像生成与设计工具。用户可以通过文字或语音指令快速生成活动邀请函、海报等视觉内容,并支持灵活的局部编辑,如修改图片元素和文字,提高设计效率。应用以网页形式上线,未来计划推出移动应用并整合到Workspace中,为用户提供更便捷的设计体验。
阶跃星辰发布图像生成编辑模型 Step Image Edit 2,银河通用机器人发布跨本体“隐式世界-动作基础模型”
本文聚焦AI与出行领域最新动态:阶跃星辰发布轻量高效的图像生成编辑模型Step Image Edit 2,银河通用机器人推出跨本体动作基础模型LDA;同时梳理滴滴、哈啰在“五一”假期出行需求预测与服务升级上的新变化,展现技术创新与消费趋势。
谷歌Gemini深度集成Google Photos,支持从相册生成个性化AI图像
谷歌近日为AI助手Gemini推出重磅更新,通过深度集成Google Photos,用户可利用相册中的真实影像生成高度个性化的AI图像。该功能由Nano Banana2模型驱动,旨在提升“个人智能”体验。尽管这一创新带来了更便捷的创作方式,但也引发了关于私域数据安全的讨论。对此,谷歌强调该功能采用自愿加入机制,且私人照片不会用于模型训练,力求在技术创新与隐私保护间取得平衡。

谷歌 Gemini 接入个人相册,AI 生成图像迈向真正个性化
谷歌宣布Gemini接入个人相册,在用户授权Personal Intelligence后可整合Google应用数据,并直接调用Google Photos中的照片进行创作。结合Nano Banana,用户无需手动上传素材,即可生成与家人场景相关的个性化图像,标志AI图像生成从通用化迈向真正个人化。

谷歌 Gemini 推出基于 Nano Banana 技术的交互式可视化图像生成新功能
谷歌 Gemini 推出基于 Nano Banana 技术的交互式可视化功能,标志着 AI 生成内容从静态图像向动态交互模拟的重要跨越。用户可通过该功能生成可操作的数字程序,实时调节参数或拆解机械结构,直观理解复杂逻辑。该功能目前面向 Gemini Pro 用户开放,在在线教育、工程模拟及科普领域具有极高的应用价值。

告别 AI 标准脸:阿里发布 Wan2.7-Image,开启“千人千面”新时代
阿里大模型团队发布Wan2.7-Image图像生成与编辑模型,突破AI生成图像的标准化限制,实现千人千面的个性化创作。该模型支持精准捏脸、色彩控制、3K Token超长文本渲染及交互式编辑功能,大幅提升创作自由度与专业内容生产效率。







