

TAG:视觉语言动作模型
LeCun与谢赛宁转发中关村学院ECCV2026世界模型与VLA共融方案VLA-JEPA
本文介绍了VLA-JEPA,一个创新的Vision-Language-Action模型预训练框架,它借鉴Yann LeCun提出的JEPA方法,在潜在表征空间中学习预测世界状态变化,而非像素级重建。该框架能有效利用有限机器人数据和丰富人类视频,关注动作导致的状态转移,减少视觉噪声影响。VLA-JEPA仅使用13条轨迹即可完成任务,展示了在少数据下的稳健性,并获得LeCun和谢赛宁的转发关注,为机器人学习提供了新思路。
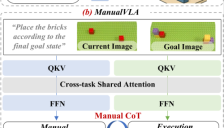
北大发布ManualVLA模型 长程精细任务成功率显著提升
北京大学联合团队提出的ManualVLA模型,通过创新的双专家架构和手册链式思维机制,显著提升了机器人在乐高组装、物体重排等长程精细任务中的规划与执行能力,平均成功率比现有最佳方案高出32%。
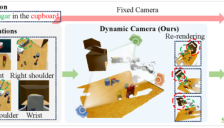
突破机器人空间感知瓶颈!中山大学与拓元智慧团队提出TAVP框架
中山大学与拓元智慧团队提出TAVP框架,通过动态视角规划和任务感知特征提取,突破机器人3D感知局限与任务干扰问题。该框架在RLBench基准测试的18项操控任务中表现优异,显著提升机器人在复杂场景下的动作预测准确性和任务泛化能力,为具身智能发展提供新思路。





美股三大指数震荡整理,芯片股走高,光通信板块大涨
2026-05-11
0 浏览
多空胶着恒指震荡整理,AI景气外溢主导行情波动
2026-05-11
0 浏览
宠物AI公司PurrPurr获阿尔法公社投资 首年GMV目标5000万
2026-05-11
0 浏览
隆源股份业绩说明会回应今年新能源汽车零部件领域新客户洽谈中
2026-05-11
0 浏览
中国品牌市占率达75%,4月我国汽车销量约252.6万辆,新能源汽车出口贡献度近五成
2026-05-11
0 浏览
4月汽车出口增长51% 国内零售下跌超20%
2026-05-11
0 浏览
4月全国新能源汽车渗透率历史首次突破60%,燃油车零售同比暴跌37%
2026-05-11
0 浏览
港股复盘:强势翻红 芯片概念股冲高回落 短期风险需警惕
2026-05-11
0 浏览
申昊科技拟设具身智能子公司 加码人形机器人业务
2026-05-11
0 浏览


