

TAG:机器人评测

大晓机器人开悟世界模型在RoboTwin 2.0等具身智能评测中位列榜首,超越Cosmos3
大晓机器人开悟世界模型(Kairos)在RoboTwin 2.0、LIBERO-Plus等多个全球权威具身智能评测中排名第一,超越Cosmos3等竞品。该模型采用创新的“多模态理解-生成-预测”一体化架构,在视频生成和状态预测方面表现卓越,并已向全行业开源,推动具身智能技术发展。

CVPR 2026|世界模型 + 真机 + 仿真同台评测!CVPR 首届具身智能顶级赛事 GigaBrain Challenge 圆满收官
本文报道首届登陆CVPR的具身智能赛事GigaBrain Challenge圆满收官,介绍其联合高校与企业举办、覆盖世界模型、真机和仿真三大评测体系的创新赛制,以及全球参赛规模、数据集下载、论文收录和各赛道获奖结果,展现具身智能评测与产业落地的新标杆。

星动纪元Era0夺冠RoboChallenge:成功率64.33%,17项任务第一
星动纪元Era0在RoboChallenge全球具身智能评测中以64.33%的成功率夺冠,在30项任务中17项获得第一。该模型通过VLA与世界模型融合、数据-模型-推理协同创新,展现了灵巧操作的技术领先性。目前已在中国邮政和顺丰物流中心常态化运营,实现了从评测到产业应用的完整路径,验证了具身智能的商业价值。
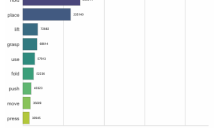
GM-100详解:真实世界机器人评测榜单从比规模转向考细节
本文详细介绍了GM-100,一个由上海交通大学等机构发布的机器人评测基准。GM-100包含100个细节导向型任务,旨在评估具身智能体在真实世界中的交互能力。它解决了传统评测中任务过于集中在常见动作的问题,通过关注动态接触、双臂协同等精细操作,更公正地衡量机器人性能,推动机器人从演示视频走向实际应用。

具身大模型:先对齐评测,再对齐世界
本文剖析具身智能“演示火热却难落地”的现状,指出仿真与现实鸿沟及评测标准缺失的痛点。文章重点介绍真实机器人评测平台RoboChallenge,通过最新测试数据揭示当前模型在精细操作上的短板,强调建立统一、客观的评测基准与排行榜是推动具身大模型从实验室走向真实世界的关键前提。

具身智能研究亟需Benchmark基础设施
具身智能研究正面临模型飞速迭代与评测体系滞后的结构性矛盾。本文聚焦CVPR 2026官方竞赛ManipArena的启动,深入剖析其作为统一真机评测基准的重要意义——通过常态化、可复现、低门槛的实机测试平台,推动具身智能从‘野蛮生长’走向系统进化,填补长期缺失的关键基础设施短板。

李飞飞与光轮智能合作 构建具身智能评测体系 仿真机器人迈入量化时代
AI先驱李飞飞创立的World Labs与光轮智能合作,构建全球首个面向具身智能的高保真、可扩展评测体系,通过仿真技术实现机器人感知、规划与执行能力的量化评估,推动行业从演示驱动迈向评测驱动,加速具身智能的商业化进程。







