

TAG:强化学习

前NVIDIA工程师用强化学习让人形机器人担任办公室实习生
前NVIDIA机器人科学家Nikita Rudin创立的瑞士公司Flexion Robotics,开发出基于强化学习的AI系统,让人形机器人真正实现自主工作。在演示中,Unitree机器人接到指令后,自主走楼梯取包裹、坐电梯、开门,并将零食整理到抽屉里。其核心是通过模拟环境大规模训练单个技能,再由主AI模型智能组合这些技能执行复杂任务。这种“软件优先”的强化学习方案,被视为解锁人形机器人商业化的关键。

图灵奖获得者-"强化学习之父"Richard Sutton教授参访北京人形机器人创新中心
图灵奖获得者、“强化学习之父”Richard Sutton教授参访北京人形机器人创新中心。他赞赏天工3.0机器人导览演示及自研关节模组,对「慧思开物」具身智能平台表现出浓厚兴趣。双方就强化学习与具身智能融合、“机器人幼儿园”项目等展开深入交流,为产业创新提供重要启示。
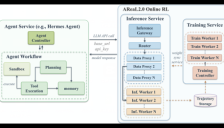
AReaL2.0开源,打造面向自演进智能体的RL基础设施
AReaL2.0正式开源!该项目为真实业务中的Agent提供在线强化学习(Online RL)基础设施,让智能体在完成任务时产生的交互、决策与反馈能安全转化为持续学习数据,实现“越用越强”的自演进能力。无需重构Agent,只需通过统一推理入口即可接入训练闭环,并内置企业级数据代理机制保障安全合规。由蚂蚁集团、清华、港科大发起,现独立开源并加入PyTorch Foundation。

前DeepMind团队创立的量化AI公司EquiLibre完成A轮融资,估值5亿美元
前DeepMind研究员创立的EquiLibre Technologies完成A轮融资,估值达5亿美元。该公司专注于强化学习在金融量化交易的应用,已与Tower Research Capital合作,在标普500、纳斯达克及加密货币市场每日执行数十亿美元交易并保持月度零亏损记录。其核心团队曾开发击败人类的扑克AI DeepStack,顾问包括2024图灵奖得主Rich Sutton,正加速AI技术在顶级金融市场的落地。

无界动力发布MWA隐空间世界模型,此前融资数亿美元并登顶权威榜单
无界动力正式发布全球首个“长时序双向物理因果链”隐空间世界模型MWA具身通用大脑,并在斯坦福等顶尖机构联合发起的RoboCasa GR1 TableTop具身智能权威榜单中荣登全球第一,超越英伟达GR00T-N1.6、大晓机器人ACE-EGO-0、小鹏DIAL等主流模型。公司坚持“隐空间世界模型+强化学习”双轮驱动技术路径,在抽象隐空间中直击物理因果本质,构建机器人“世界观”与“价值观”,MWA创新双向动力学与Chunk级逆向建模,实现长时序连贯精准执行,已在工业、商业及家庭多元场景形成数据飞轮,加速具身

实探龙旗科技产线:人形机器人从演示走向工业应用仍需补短板
本文实地探访龙旗科技南昌工厂,深入报道了人形机器人智元精灵G2在平板质检产线中的实际应用。文章详细分析了机器人通过二维码定位和强化学习完成上下料工作,探讨了人形机器人相比传统机械臂的通用性优势,如能灵活调整岗位适应订单波动,同时也指出数据缺乏是当前人形机器人发展的主要短板,限制了其大脑能力的提升,为评估人形机器人能否成为真正生产力提供了关键见解。

Ted谈机器人十年:DeepMind研究者的信念修正历程
本文通过DeepMind前研究科学家Ted Xiao的视角,回顾了具身智能领域近十年的技术演进与关键转折。核心探讨了机器人学习如何从过度依赖强化学习,转向通过高质量专家数据实现行为克隆的突破,并分析了RT-1、RT-2等基础模型如何让机器人继承互联网大模型的知识。文章深入剖析了技术路线调整背后的实践反思,对理解当前具身智能的发展逻辑具有重要参考价值。

光象科技CEO张涛:让机器人进工厂从事艰苦工作
光象科技CEO张涛在采访中阐述了公司让机器人进工厂干“苦活累活”的愿景,发布了工业级自进化具身智能机器人Phi-Bot X1。文章聚焦于光象科技选择汽车制造作为首个落地场景,通过强化学习和数据闭环技术,强调机器人在真实工业需求中的应用价值,而非行业热门叙事。这展示了具身智能在推动工业自动化方面的实际进展。

Wayve CEO在CVPR 2026上强调自动驾驶是通向10亿机器人的第一块试验田
在CVPR 2026上,Wayve创始人Alex Kendall展示其最新路线图:自动驾驶并非孤立汽车工程,而是通往10亿真实机器人AI的“第一块试验田”。演讲核心包括AV2.0端到端模型、强化学习回归中心、GAIA-3可控世界模型,以及“四日循环”研发闭环。Wayve已获奔驰、日产、Stellantis等合作,强调泛化、成本效率与仿真-现实闭环,为具身智能规模化提供可落地路径。

人形机器人动作日趋丝滑:详解全身控制技术发展路线
本文深入解析人形机器人动作从僵硬到丝滑的核心技术——全身控制。文章详细介绍了ZMP用于稳定行走的基础阶段,以及HQP实现动态全身协调的进阶阶段,探讨了机器人如何通过整合腿、腰、手臂等部分的动力学,实现整体协作以适应复杂任务。全身控制的发展使机器人动作更自然、流畅,标志着控制技术从简单模拟向智能动态演进。
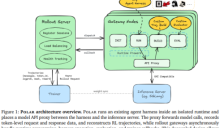
英伟达开源 Polar 框架,助力 AI 编码智能体实现强化学习零门槛进化
英伟达开源了Polar强化学习训练框架,使AI编码智能体如Codex和Claude Code无需修改原生代码即可接入GRPO训练。该框架通过透明代理拦截API请求并重构训练轨迹,解决了传统方法的高成本和信息丢失问题。实验显示,在SWE-Bench测试中性能大幅提升,训练效率显著优化,为AI智能体进化提供标准化路径。

波士顿动力90公斤机器人搬运45公斤冰箱 网友称比搬家还稳
波士顿动力的新版Atlas人形机器人展示了颠覆性的搬运能力,能轻松搬起45公斤的冰箱,打破了机器人只能做轻活的刻板印象。文章深入探讨了其背后的物理智能技术,包括全身体感与力反馈的融合、强化学习训练方法,以及硬件设计从液压转向电驱的变革,同时介绍了商业化部署计划,预示着人形机器人即将进入工厂实际应用的新阶段。


行为克隆训练机器人通过强化学习在2小时内实现自我进化
本文探讨了机器人行为克隆策略的局限性及其在遇到新场景时的崩溃问题,以及传统强化学习的高成本挑战。文章介绍了一种名为Q2RL的新方法,它从已有的BC策略中提取价值判断,作为在线强化学习的起点,无需原始训练数据或离线预训练。通过让BC和RL策略在决策中竞争,Q2RL能在较短时间内(如2小时)提升机器人性能,为机器人学习提供高效且实用的解决方案。

谷歌SkillOS新框架让AI智能体实现自我进化
谷歌云AI研究院提出SkillOS框架,通过强化学习训练技能策展器,让AI智能体在持续学习中主动管理技能库,实现自我进化。该框架解决了传统技能库依赖固定规则、冗余严重的问题,采用GRPO算法和课程式分组训练,提升技能的可复用性和泛化能力,使Agent能从经验中提炼可复用技能,真正学会跨任务迁移。

具身大模型R1时刻:LIBERO终结者实现99.9%物理推理新范式
本文介绍了具身大模型的新突破LaST-R1,它通过隐空间物理推理和强化学习优化,使机器人在行动前进行物理思考,而非简单模仿。在LIBERO benchmark上达到99.9%成功率,真机任务中比现有最强模型π0.5高出22.5%,显著提升了泛化能力。这一范式解决了传统模型在环境变化时失效的问题,为机器人操作提供了更稳定的物理推理基础。







