

TAG:开源模型

商汤开源视觉模型 SenseNova-Vision-7B-MoT,带来新突破
商汤开源多任务视觉模型 SenseNova-Vision-7B-MoT,将目标检测、OCR、深度估计、分割、多视图处理等能力统一到7B参数框架中,并开放权重、5000万样本子集与复现工具,为视觉理解和GUI智能体研发提供高扩展性的基础模型支持。

腾讯混元发布 HyOCR-1.5:仅 1B 参数,推理速度提升 6.37 倍
腾讯混元发布全栈开源端到端OCR模型HyOCR-1.5,以仅1B参数实现高性能文档识别,并借助DFlash投机解码将推理速度最高提升6.37倍。文章重点介绍其开源价值、训练创新及在复杂文档、古文字和图表解析等场景中的越级表现。

AI“下半场”赛道已变:不再只比谁更大、更强
AI“下半场”的赛道已悄然改变。过去两年,AI领域以模型规模越大、基准测试越好论英雄。如今,企业从单纯测试转向实际产品落地,核心不再是追求最强模型,而是以合理成本、特定环境匹配最适合任务的模型。Perplexity CEO Aravind Srinivas强调,关键在于构建智能“框架”,实现模型路由、工具调用与数据整合。开源模型(尤其是中国智谱GLM 5.2)崛起,预计将主导90% Token生成,对OpenAI等巨头定价能力构成挑战,并推动本地混合部署与AI基础设施变革。

蚂蚁灵波四天六发 为机器人装上原生大脑
蚂蚁灵波四天六发六款LingBot 2.0开源模型,核心收官之作是业界首个具身原生动作模型LingBot-VA 2.0。构建感知-决策-执行-仿真完整闭环,告别视频生成模型嫁接做法,从零为物理世界设计原生大脑,已登上国际热榜并开启商业落地,加速机器人产业化进程。

英伟达将与 Hugging Face 合作开发机器人开源模型
英伟达宣布与Hugging Face合作,联合开发用于机器人的开源基础模型。该合作整合GPU生态与CUDA技术,借助Hugging Face庞大的模型库和开发者社区,大幅降低机器人AI训练与部署门槛,为行业带来重大价值。
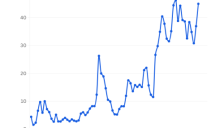
中国大模型在美悄然崛起 企业发现极致性价比更诱人
中国AI大模型正在美国悄然崛起!DeepSeek、智谱GLM等中国开源模型在性能接近OpenAI和Anthropic前沿水平的同时,成本仅为其1/10至1/3,展现极致性价比。OpenRouter数据显示美国企业使用比例从4.5%飙升至30%以上,Lindy公司全面切换后每年节省数百万美元,Vercel平台采用量暴增。这一“价格才是关键”的趋势,正重塑美国企业AI采用策略。
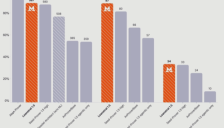
降低数学科研门槛:Mistral AI 发布开源模型 Leanstral 1.5
Mistral AI 发布开源模型 Leanstral 1.5,专为数学形式化证明语言 Lean4 设计。该模型以119B参数和6B激活参数实现高性能与低成本,在 miniF2F、PutnamBench 和 FATE 等基准测试中取得创纪录成果,平均求解成本仅4美元,远低于同类模型。此外,它还能识别代码库中的真实漏洞,助力科研人员高效突破数学证明瓶颈。

Step 3.7 Flash、DeepSeek、MiniMax、Gemini、GPT,谁更适合Agent?-资讯中国
本文实测对比Step 3.7 Flash、DeepSeek v4、MiniMax、Gemini 3.5与GPT在Agent场景的真实表现。使用相同提示词和Trae Work工具,完成短视频平台调研PPT自动生成和浏览器信息抓取两大任务。从工具调用准确性、稳定性、速度、成本、输出质量(内容组织与视觉效果)多维度评估。结论显示Step 3.7 Flash在生产级高频Agent中平衡性最佳,国内模型性价比优势明显,为开发者选型提供实战参考。

Qwen 3.6 27B评测显示本地模型性能已达前沿水准,媲美GPT-5
本文评测了Qwen3.6 27B本地大模型的性能表现,显示其在智力水平上已接近或对标GPT-5、Claude Sonnet 4.5等顶级付费模型。在MacBook上实测达到稳定32tok/s速度,并能在复杂任务中高质量完成,如写诗和生成游戏。文章强调本地模型在成本、隐私和掌控感方面的优势,标志着消费级硬件运行的开源模型已迎来重要拐点,值得开发者和创作者关注。
美国科技巨头为何悄然转向中国大模型?
美国科技巨头因成本压力纷纷转向中国开源大模型,Coinbase率先采用智谱GLM和月之暗面Kimi,在Token用量激增下节省近半AI开支。Airbnb等企业也跟进,中国模型凭借高性价比在海外走红,悄然改变全球AI基础设施布局。

阿里开源统一科学大模型LOGOS,仅用五十六分之一参数超越微软
阿里联合中国人民大学开源首个基于统一科学语法的多领域科学生成基础模型LOGOS。该模型采用纯序列建模范式,在六大科学任务中匹配或超越传统领域专用方法,仅1B参数量即超越微软8×7B的NatureLM模型,展现极高参数效率。LOGOS设计统一科学语法,将生物大分子、化学实体等异构对象编码为离散Token序列,消除预训练与应用断层,开源提供模型权重、代码和技术报告,推动科研AI发展。

SOTA刷新:具身模型ACE-Ego正式开源,解析机器人如何看懂人类动作
大晓机器人联合港中文发布并开源具身操作VLA模型ACE-Ego,在RoboCasa与RoboTwin两大基准刷新SOTA。文章解析其通过第一视角人类视频与机器人数据联合预训练的关键方案,以及在零售打包、装盒等复杂场景中的落地表现与泛化价值。

智谱AI正式开源GLM-5.2模型,主打1M无损上下文与长程代码任务
智谱AI正式开源GLM-5.2,重点面向代码生成与长程任务执行,支持1M无损上下文和多端应用开发。文章介绍了其在Code Arena、FrontierSWE等评测中的表现,以及架构优化、国产算力适配和开源生态价值。
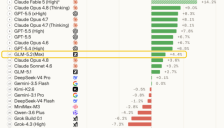
微软考虑采用开源模型降低智能体费用
微软正考虑采用开源AI模型如DeepSeek V4来降低其智能体产品Copilot Cowork的费用,以应对按使用量计费导致的高成本问题。文章指出开源模型可大幅节省开支达90%以上,并探讨了AI支出下滑趋势及中国大模型在开源领域的竞争优势,为行业提供更经济实用的解决方案。

国产大模型海外榜单斩获多项第一,阶跃星辰、智谱、MiniMax面临破局挑战。
阶跃星辰的开源模型Step 3.7 Flash在海外评测平台Artificial Analysis上斩获多项第一,包括输出速度领先,展现国产大模型在技术效率上的突破。模型针对生产级Agent应用优化,强调速度与能力的平衡。然而,面对智谱和MiniMax等竞争对手的激烈角逐,阶跃星辰在产品生态和开发者触达方面存在挑战。专家指出,破局关键在于构建可防御的生态护城河,而非仅依赖技术优势。







