

TAG:大语言模型

Anthropic Claude系列大模型正式入驻Microsoft Foundry,全面托管于Azure云平台
Anthropic旗下Claude系列大模型正式登陆Microsoft Foundry并托管于Azure云。企业客户可通过现有Azure账户直接调用Claude模型,复用微软治理体系,简化采购合规流程。该服务支持提示缓存、扩展思考及数据驻留选择等功能,运行于NVIDIA Blackwell Ultra系统之上。Bolt等企业已基于此构建生产系统。此合作标志着前沿大模型与顶级云基础设施的深度融合,为企业级AI落地提供全新范式。

Anthropic发布大模型Claude Sonnet 5:性能逼近旗舰,价格大幅下调
Anthropic推出全新大语言模型Claude Sonnet 5,性能逼近旗舰Opus系列,但价格大幅降低。该模型具备强大的自主代理能力,能规划复杂任务、调用外部工具,同时幻觉率和讨好式回应下降,安全性提升。目前已作为免费和Pro计划默认模型,旨在以低价策略让更多用户享受顶尖AI体验。

杨立昆称马斯克的xAI已成失败案例 行业或面临泡沫破裂风险
杨立昆,图灵奖得主及AI教父,近期公开批评马斯克的xAI公司为失败案例,指出其团队流失、竞争劣势。他进一步质疑全球AI行业的高估值,警告因AI成本高企、公司亏损严重,行业可能面临巨大的泡沫破裂。文章还探讨了杨立昆对大语言模型的批评以及对世界模型技术的看好,为AI发展和投资提供了批判性视角。

北航联合团队提出RoboSafe,保障具身智能体物理世界安全行动
本文介绍了北航联合团队提出的RoboSafe框架,该框架通过可执行安全逻辑为具身智能体提供安全护栏,有效识别和处理情境风险与时序风险。RoboSafe利用前向预测推理和后向反思推理两个模块,在动作执行前检测潜在危险,并在仿真和真实机械臂实验中验证了其防护效果,显著降低了危险执行率,提升了机器人在物理世界中的行动安全性。

腾讯与人大高瓴联合开发开源规划评测框架 PlanningBench
腾讯混元团队与人大高瓴人工智能学院联合推出开源规划评测框架 PlanningBench,旨在系统化评测和训练大语言模型的规划能力。该框架抽象出30多种规划任务类型(如日程排布、资源分配、人力排班等),通过可验证数据生成与Checklist评估,精确诊断复杂约束下的真实规划能力。训练后模型在未见任务上表现显著提升,为AI规划研究提供真实场景闭环工具。

OpenAI科学家Noam Brown:AI的真正上限可能根本没人测得起
OpenAI科学家Noam Brown指出,AI模型能力越来越依赖推理阶段的计算资源(如token数量、费用和时间)。传统基准测试的单一分数已无法准确反映真实表现,尤其在长链推理、网络安全等复杂任务中。他建议转向“性能—推理计算量曲线”评估方式,帮助行业更科学地理解模型上限与成本效益。

顾全全确认从字节Seed团队离职,曾主导SeedFold与Seed2.0训练体系建设
字节跳动Seed团队核心研究员顾全全确认离职,结束了其三年的工作。他回顾了在AI药物发现领域的贡献,包括主导研发超越AlphaFold3的SeedFold模型和蛋白质设计工具,同时在大语言模型预训练方面搭建了Seed2.0训练体系。离职正值字节AI业务商业化加速阶段,引发外界对AI for Science创业热潮的广泛关注,业内普遍预测他将投身AI制药等前沿领域的创业。

腾讯云智能体开发平台集成DeepSeek
腾讯云智能体开发平台宣布自2026年6月3日起大幅下调DeepSeek-V4系列模型的调用价格,其中DeepSeek-V4-Pro的缓存命中价格降幅高达97.5%。具体调整包括DeepSeek-V4-Pro的推理输入和输出价格下调75%,缓存命中价格调整;DeepSeek-V4-Flash的缓存价格降幅90%。作为今年4月发布的1.6万亿参数大模型,采用MoE架构并支持长上下文,此次降价让开发者能以更低成本使用先进AI能力,降低应用开发成本,提升效率。

剑桥团队推出AI Agent一天生成10000个3D模型并能自主运动
剑桥大学和牛津大学团队开发的Articraft系统,利用大语言模型直接编写代码生成可活动的3D模型。该系统能在24小时内生成超过1万个模型,覆盖笔记本电脑、无人机等多种类别,通过专用SDK和验证机制实现高效、低成本建模,平均每个模型成本约1.97美元。研究显示其生成质量优于现有方法,并创建了大规模数据集Articraft-10K,用于提升3D物体理解模型的性能。
最新研究表明人们普遍认为人工智能比人类更自信
滑铁卢大学与伦敦大学学院的最新研究发现,人们普遍认为人工智能比人类更自信,即使两者给出的答案完全一致。这种现象被称为'自信错觉',源于AI的快速响应和缺乏情感信号,加上人们对AI的固有偏见,可能导致用户盲目信任。研究强调,未来AI系统需要新增自信度明示功能,以清晰传递真实把握程度,帮助用户更理性地评估建议,避免误判和过度依赖。
网易有道云笔记发布“LLM Wiki”套件,聚焦AI时代知识管理升级
网易有道云笔记推出“LLM Wiki”技能套件,以大语言模型重构知识管理:从传统“记录+搜索”的被动检索,升级为能理解、关联、归纳碎片信息的“知识增量编译器”。该方案为个人与企业打造更高效的第二大脑与智能协作办公提供底座。
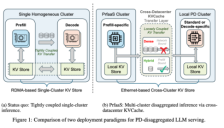
Moonshot AI与清华大学提出跨数据中心PrfaaS创新架构
本文介绍了 Moonshot AI 与清华大学提出的 PrfaaS(预填充即服务)架构:将大模型推理中的预填充与解码阶段跨数据中心解耦,借助专用计算集群与以太网传输 KVCache,突破传统同中心部署瓶颈。研究显示该方案可将吞吐量提升54%,并通过分层路由与双时间尺度调度降低延迟、提升资源利用率。

Nature重磅论文揭示AI“隔空传毒”风险:不良特征可藏于纯数字并在蒸馏中传播,模型安全链面临失守
Nature最新研究揭示LLM“潜意识学习”风险:即使训练数据是纯数字、代码或无关思维链,模型蒸馏仍可能把上游模型的不良特征隐性传给下游,导致传统语义过滤与安全评估失效。文章解析其数学机制与供应链投毒隐患,强调AI安全应从“看输出”升级为“查权重”。

苹果开办内部训练营,详解Siri进化底座,目标打造真正的AI个人助理
苹果启动面向 Siri 团队的内部“AI 编程训练营”,系统补齐 LLM 工程能力,覆盖 Prompt、RAG、Agent 与低延迟推理,并强调端云协同、离线推理和隐私安全。此举意在推动 Siri 与系统应用深度融合,加速其从语音指令工具进化为多模态“AI 个人助理”,回应外界对苹果 AI 进展的质疑。
哈佛最新研究:AI大型语言模型用于看病时初步诊断错误率达80%
哈佛医学院团队评估ChatGPT、DeepSeek、Gemini、Claude等二十余种大型语言模型的看病能力,发现仅凭初步症状进行鉴别诊断错误率高达80%,补充检查信息后最终诊断失败率仍约40%。研究指出AI需完整病历与检测数据支持,且尚不能替代医生独立作出诊断决策。







