

TAG:大模型评测
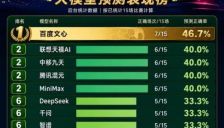
世界杯成AI公开考场,中国移动九天亮相人机大战并跻身领先梯队
文章以世界杯预测“人机大战”为切口,分析12家大模型在统一公开赛场中的阶段表现,重点关注中国移动九天跻身领先梯队的意义,并讨论复杂技术方案、预测准确率和平局场景难题,展现大模型走向真实场景后的真实差异与价值。

DeepSeek-V4爆火背后:北大开源框架One-Eval如何终结AI测评“噩梦”
本文聚焦DeepSeek-V4发布后北大DCAI团队10小时完成自动化评测的案例,解析开源框架One-Eval如何以自然语言智能体、全链路可追溯与人工在环机制,破解大模型评测中的高门槛、黑盒与数据污染难题,并揭示评测产业“诊断+数据补全”的商业闭环及开源带来的行业变量。
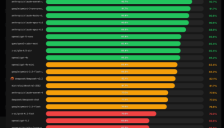
AI编码工具战力榜揭晓 OpenClaw小龙虾领跑
OpenClaw最新发布的“小龙虾AI Agent排行榜”对主流大模型在真实编码任务中的表现进行了全面评测。榜单采用标准化测试方法,通过自动化代码检查和LLM智能评审双重机制,客观评估各模型的实际编码能力。Gemini3Flash、MiniMax M2.1和Kimi K2.5位列前三,Claude家族表现亮眼,而GPT-5.2和DeepSeek的成绩则出人意料。这份榜单为开发者选择AI编码助手提供了重要参考。

OpenClaw AI助手是否值得一试
本文通过《每日经济新闻》记者与开发人员的深度实测,评估了号称“AI打工人”的OpenClaw工具的实际表现。测试将其接入多款主流大模型,包括千问、Kimi、MiniMax、智谱和GPT-5-mini,考察其在文件检索、网络搜索、稿件撰写和邮件发送等任务中的能力。结果显示,不同模型表现差异显著,部分模型在关键环节如浏览器操控上存在困难,揭示了当前AI Agent在实用性、稳定性和信息安全方面面临的挑战。





美股三大指数震荡整理,芯片股走高,光通信板块大涨
2026-05-11
0 浏览
多空胶着恒指震荡整理,AI景气外溢主导行情波动
2026-05-11
0 浏览
宠物AI公司PurrPurr获阿尔法公社投资 首年GMV目标5000万
2026-05-11
0 浏览
隆源股份业绩说明会回应今年新能源汽车零部件领域新客户洽谈中
2026-05-11
0 浏览
中国品牌市占率达75%,4月我国汽车销量约252.6万辆,新能源汽车出口贡献度近五成
2026-05-11
0 浏览
4月汽车出口增长51% 国内零售下跌超20%
2026-05-11
0 浏览
4月全国新能源汽车渗透率历史首次突破60%,燃油车零售同比暴跌37%
2026-05-11
0 浏览
港股复盘:强势翻红 芯片概念股冲高回落 短期风险需警惕
2026-05-11
0 浏览
申昊科技拟设具身智能子公司 加码人形机器人业务
2026-05-11
0 浏览


