

TAG:多模态模型

OpenAI再失大将:田永龙疑似加盟腾讯混元,将执掌多模态方向
OpenAI前研究员田永龙疑似加盟腾讯混元,将执掌多模态模型方向。这是继姚顺雨之后,第二位OpenAI核心人才转投腾讯。田永龙拥有清华、MIT顶级履历,Google Scholar引用近2.9万次,曾提出有监督对比学习重要工作。其加入加速腾讯混元多模态团队人才拼图成型,彰显腾讯通过“OpenAI校友网络”在AI人才争夺战中的强势布局。

OpenAI前研究员田永龙加盟腾讯混元多模态团队
OpenAI前研究员田永龙(Yonglong Tian)已加入腾讯混元团队,或将出任多模态模型方向负责人,主导视觉语言模型(VLM)研发。田永龙学术背景深厚,本科毕业于清华大学,MIT博士,Google Scholar引用近3万次。他提出的“有监督对比学习”(Supervised Contrastive Learning)影响深远,近期在Fluid系列自回归图像生成领域取得突破。此前曾在Google DeepMind和OpenAI任职,与腾讯首席AI科学家姚顺雨为旧识。此次加盟是腾讯加强多模态大模型布局的

商汤科技秘密研发多模态模型U1Pro,由林达华牵头,预计7月启动内测并对标OpenAI
商汤科技正秘密研发多模态大模型U1Pro,由首席科学家林达华牵头,预计7月启动内测。该模型专注于设计场景,对标OpenAI的GPT-Image2,具备长程逻辑能力和8K超清输出,内部测试效果接近甚至超越GPT-Image2。这标志着AI图像生成技术正从娱乐向专业生产力工具演进,并加速多模态大模型在设计领域的竞争。
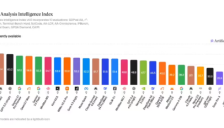
国产多模态大模型 MiniMax M3 正式开源,响应速度倍增
稀宇科技MiniMax正式开源其原生多模态旗舰模型M3,该模型拥有428B总参数,是行业内首个从底层训练初期即进行多模态混合训练的开源大模型。发布后迅速在全球综合智能指数排行榜上斩获开源模型第一,响应速度从30 TPS优化至80 TPS。M3在编码与智能体能力评测中表现顶尖,能自主拆解复杂任务并调用工具,输出代码可直接交付,显著提升开发者生产力,标志着国产多模态大模型的重要里程碑。
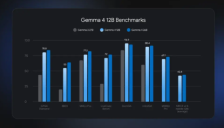
谷歌发布Gemma 4 12B模型,支持16GB内存本地即时响应,采用无编码器架构
谷歌发布Gemma 4 12B多模态模型,采用颠覆性“无编码器”架构,彻底取消传统编码器组件,大幅降低模型复杂度和内存需求。该模型仅需16GB内存即可在消费级硬件上本地部署和即时响应,性能接近更大规模模型。作为开源项目,它支持多种推理框架,推动本地AI应用的普及,引发社区热议。
火山引擎发布业界首个Agent套餐包,整合多模态模型与联网工具
火山引擎发布业界首个Agent套餐包Agent Plan,整合自研及第三方多模态模型,并集成联网搜索等工具,采用Model与Harness双驱动模式。该计划引入AFP统一计量,提供阶梯订阅,旨在降低Agent应用开发门槛,加速AI在短视频制作、自动化办公等场景的爆发,标志着大模型竞争从参数转向生态集成。

英伟达推出新一代多模态模型,智能体效率提升九倍
英伟达发布开放式多模态模型 Nemotron 3 Nano Omni,将视频、音频、图像与文本推理整合到统一系统中,凭借混合专家架构实现最高9倍吞吐提升,并在文档解析、视频理解等任务中表现领先,展现出智能体应用的广阔前景。

英伟达发布多模态全能模型,称智能体效率提升至竞品9倍
英伟达发布开放式多模态模型Nemotron 3 Nano Omni,可整合视频、音频、图像与文本推理能力,显著提升智能体响应速度与部署效率。该模型采用混合专家架构,号称吞吐量达同类竞品9倍,并在复杂文档、视频和音频理解等多项榜单中领先。
研究人员推出LPM1.0模型,实现单图转实时交互式数字人视频
LPM1.0模型实现了通过单张参考图像生成实时交互式数字人视频。该模型支持多模态输入,具备精准唇形同步与自然情绪表达,可与ChatGPT等AI集成实现实时视觉对话。凭借核心技术,它能即时驱动多种风格角色且无需二次训练。该研究标志着AI交互正向具备情感响应与视觉具身化的全维度形态演进,具有重要的科研价值。
Meta发布Muse Spark个人超级智能模型:算力节省10倍 经千人医生训练 支持拍照识别数独、可提供专业级健康咨询服务
Meta正式发布Muse系列首款个人超级智能模型Muse Spark。该模型采用原生多模态架构,算力效率较Llama4Maverick提升10倍。Muse Spark凭借多智能体并行推理与深度视觉能力,可实现拍照出数独等复杂交互,更通过千人医生联合训练提供专业健康建议。目前模型已在Meta.ai及应用端上线,标志着个人AI智能进入低能耗、高专业度的新阶段。
可灵AI推出会员模型优惠计划:3.0系列视频模型限时8折起
可灵AI推出会员模型优惠计划,2026年4月至6月期间,3.0系列视频模型限时8折起,铂金及以上会员享专属折扣,部分图片功能低至免费。此举旨在降低高阶视频创作门槛,推动AIGC向规模化生产力转型,反映AI视频生成领域从算力竞争转向用户生态与成本优化的新趋势。
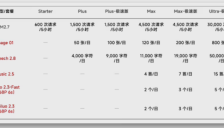
MiniMax推全球首款全模态订阅服务 视频语音绘图全包
MiniMax重磅推出全球首个全模态订阅计划Token Plan,全面整合视频、语音、图像与音乐生成模型,实现加量不加价,并支持最新M2.7编程模型与OpenClaw生态深度集成,助力开发者与创作者降本增效,开启AI生产力新纪元。

英伟达推出Nemotron 3系列开源模型 推理效率提升5倍
英伟达在2026 GTC大会上发布Nemotron 3系列开源模型,凭借Blackwell架构优化,推理效率提升5倍。新模型涵盖多模态交互、物理AI、机器人及医疗科研领域,支持从云端到边缘的快速部署,助力智能体与具身智能发展。

AI革新影视配音 通义开源Fun-CineForge攻克多人对话
通义实验室开源影视级多场景配音大模型Fun-CineForge,突破传统AI配音瓶颈,实现口型同步、情绪表达、音色一致性和时间对齐四大核心挑战。该模型首次引入时间模态,结合视觉、文本和音频多模态融合,填补了多人对话配音的空白,在影视、动画等高要求场景中表现卓越。

OpenRouter推出匿名模型Hunter Alpha和Healer Alpha 支持1T参数与多模态输入
OpenRouter 平台上线了两款匿名新模型 Hunter Alpha 和 Healer Alpha,分别拥有最高 1T 参数量和 262K token 上下文窗口,支持多模态输入。两款模型均被推测与智谱AI相关,具备强大的推理与执行能力,目前免费使用。







