

TAG:基准测试
智能体进化新标杆:字节Seed发布EdgeBench基准测试
字节Seed团队正式发布EdgeBench超长程基准测试,为AI智能体在真实世界中的持续学习能力提供全新量化标准。该基准包含134个跨六大领域真实任务,每个任务需持续12小时以上,基于3.8万小时数据发现智能体学习遵循log-sigmoid曲线(R²=0.998),学习速度每3个月翻一番,已开源51个任务及框架。
OpenAI 发布 GeneBench-Pro 基准测试,提升 AI 模型生物学分析能力
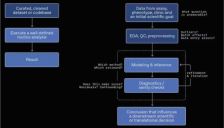
OpenAI发布GeneBench-Pro基准测试,旨在评估AI模型在基因组学、蛋白质组学等生物学任务中的实际分析能力。与传统基准不同,GeneBench-Pro模拟真实科研中模糊、不完整和带干扰的数据环境,测试模型的判断与决策能力。涵盖129道题目,涉及统计遗传学、功能基因组学等领域,采用合成数据避免评分偏差。已开源10道示例题,计划独立评测。
上海交大等团队推出SWE-Explore基准测试,揭示AI编码智能体行级定位缺陷
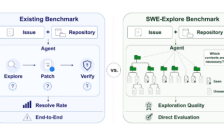
上海交大等团队推出 SWE-Explore 基准测试工具,首次解耦代码搜索与修复评估,量化揭示 AI 编码智能体在行级精度上的重大缺陷。研究基于 GPT-5.4、Claude 等主流模型,构建 203 项目 848 缺陷任务数据集,结果显示文件级定位优秀但行级覆盖率仅 14%-19%。消融实验证明上下文阈值(50%-75%)对修复成功率的影响,为 AI 软件工程评测提供全新标准,推动精准检索范式发展。

具身智能首项行业标准出台
中国信息通信研究院联合40余家单位发布具身智能领域首个行业标准,构建统一基准测试框架,明确系统框架和能力要求。标准涵盖仿真和真实环境测试方法,支持基础能力、认知推理及全链路闭环能力评测,并配套建设1万多条测试任务库和自动化工具,将于2026年6月实施。

Cursor Composer 2编码性能挑战Claude Opus 4.6 基准测试引AI编码界热议
Cursor 最新发布的 Composer 2 编码模型在 Terminal-Bench 2.0 测试中以 61.7% 的成绩超越 Claude Opus 4.6,引发 AI 编码圈热议。文章详细对比了多项基准测试数据,并分析了 Composer 2 在性价比上的优势,成本仅为 Opus 4.6 的十分之一。同时探讨了 AI 编码工具赛道的发展趋势和开发者反馈。

密歇根斯坦福联手Figure AI推出机器人记忆基准RoboMME
密歇根大学、斯坦福大学与Figure AI联合发布机器人记忆基准RoboMME,首次系统性地将机器人记忆能力划分为时间、空间、物体和程序四大维度,涵盖16项任务与770k高质量时序数据。该基准强制机器人进行历史依赖推理,破解传统评估碎片化难题,并通过14种VLA模型对比揭示不同记忆表征的适用场景,推动具身智能向更复杂现实任务迈进。

AI代码通过率或被高估7倍 基准测试难反映真实能力
METR最新研究表明,AI编程能力的基准测试SWE-bench Verified可能显著高估了AI在真实软件开发中的表现。研究发现,约一半在基准测试中通过的AI代码在实际项目维护者审核时会被拒绝,主要由于功能性错误和代码质量问题。研究还揭示了不同AI模型的表现差异,并指出基准测试可能存在高达7倍的能力高估。

AI测试过度侧重编程 忽视九成真实劳动力需求
卡内基梅隆大学与斯坦福大学的最新研究指出,当前AI智能体测试过于集中在编程领域,忽视了92%的非编程劳动力市场需求。研究发现现有基准测试严重偏向编程任务,而管理、法律等高数字化职业的测试占比极低。专家呼吁AI测评应向更广泛的经济领域扩展,以充分发挥AI的生产力价值。
Claude Opus 4.6 登顶AI智商基准测试
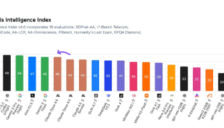
根据最新发布的Artificial Analysis智能指数,Anthropic的旗舰模型Claude Opus 4.6在编程、代理任务和科学推理等十项深度测试中表现卓越,力压GPT-5.2登顶权威排行榜。文章分析了Opus 4.6在效率、成本及性能上的优势,同时指出OpenAI的Codex 5.3可能带来的挑战,揭示了大模型竞争格局的持续动态。
Zoom联邦AI登顶全球最难AI考试
视频会议巨头Zoom凭借其创新的联邦式AI方法,在被誉为“人类最后的考试”的顶级AI基准测试中以48.1%的成绩刷新世界纪录,超越了谷歌等模型巨头。文章深入探讨了Zoom如何通过集成多个外部AI模型而非自研大模型来实现这一突破,并分析了业界对此策略的争议及其商业价值,同时展望了即将上线的AI Companion3.0的实战应用前景。


中国具身大模型发展路径初探:自变量探索可复制模式
文章探讨了中国具身大模型的发展路径,以自变量开源模型WALL-OSS在RoboChallenge基准测试中的优异表现为例,分析了开源策略如何推动行业协同与商业化进程。文章指出,开源模型通过提供完整解决方案,赋能全球开发者,加速具身智能从实验室走向现实应用,并强调了统一评测标准对行业发展的关键作用。
Meta首席AI科学家揭露Llama 4发布前伪造测试数据,引发行业震动
Meta首席AI科学家Yann LeCun承认,Llama4发布前曾篡改基准测试结果,使用不同模型针对测试项目以提升分数,导致实际性能远低于宣传。这一造假事件引发Meta内部动荡,团队被边缘化、核心人员离职,暴露了企业在技术竞争与诚信之间的艰难平衡。
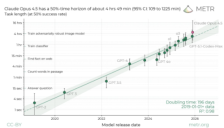
Anthropic旗舰模型Claude Opus4.5刷新长任务处理纪录
Anthropic旗舰模型Claude Opus4.5在METR基准测试中创下长任务处理新纪录,能在保持50%成功率的前提下持续处理约4小时49分钟的复杂任务,展现了AI从短指令回复向长程项目执行的转型潜力。
谷歌发布FACTS基准测试 顶尖AI模型准确率均不足七成
谷歌与Kaggle联合发布FACTS基准测试,旨在评估生成式AI模型在企业任务中的事实性与真实性。测试结果显示,包括Gemini3Pro、GPT-5和Claude4.5Opus在内的所有顶尖模型综合准确率均低于70%,尤其在多模态任务中表现不佳。该基准测试涵盖参数、搜索、多模态和上下文四个子测试,为企业AI采购提供了新的评估标准,并强调了RAG系统在提升准确性中的必要性。

MIT 新创公司 OpenAGI 推出 AI Agent,声称超越 OpenAI 与 Anthropic
麻省理工学院初创公司OpenAGI推出AI代理Lux,在计算机操作基准测试中取得83.6%的成功率,显著超越OpenAI和Anthropic的同类产品。Lux采用独特的Agent主动预训练方法,通过解析计算机截图自动执行桌面应用操作,成本仅为竞争对手的十分之一,且具备内置安全机制。







