

TAG:在线学习

行为克隆训练机器人通过强化学习在2小时内实现自我进化
本文探讨了机器人行为克隆策略的局限性及其在遇到新场景时的崩溃问题,以及传统强化学习的高成本挑战。文章介绍了一种名为Q2RL的新方法,它从已有的BC策略中提取价值判断,作为在线强化学习的起点,无需原始训练数据或离线预训练。通过让BC和RL策略在决策中竞争,Q2RL能在较短时间内(如2小时)提升机器人性能,为机器人学习提供高效且实用的解决方案。


RL Token攻克VLA精度难题 在线强化学习助机器人精准操控
RL Token提出一种创新的在线强化学习框架,通过轻量级接口让预训练VLA模型在真实机器人上实现高精度操作的快速优化。该方法在保持泛化能力的同时,解决了传统方法在‘最后一厘米’精度任务中的效率与稳定性难题,为机器人灵巧操控提供了高效、可落地的技术路径。

智元SOP突破机器人训练瓶颈 VLA模型实现分布式在线后训练
智元机器人提出的SOP系统是一种可扩展在线后训练框架,旨在解决VLA模型在真实世界部署中面临的挑战。该系统通过闭环的Actor-Learner架构,利用异构机器人集群持续采集交互数据,实现云端集中优化和分钟级参数同步,从而在保持模型通用性的同时提升任务执行熟练度。研究表明,SOP能显著提升VLA模型性能,且效率随机器人规模扩大而线性增长。
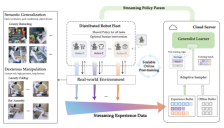
智元发布机器人部署新规 加速规模化智能运行
智元具身研究中心发布SOP(Scalable Online Post-training)系统,旨在解决机器人在真实世界规模化部署与智能化运行的挑战。该系统通过分布式在线后训练框架,实现多机器人并行探索、云端集中更新与即时参数同步,显著提升任务成功率和泛化能力,使机器人集群能在复杂环境中持续进化。





美股三大指数震荡整理,芯片股走高,光通信板块大涨
2026-05-11
0 浏览
多空胶着恒指震荡整理,AI景气外溢主导行情波动
2026-05-11
0 浏览
宠物AI公司PurrPurr获阿尔法公社投资 首年GMV目标5000万
2026-05-11
0 浏览
隆源股份业绩说明会回应今年新能源汽车零部件领域新客户洽谈中
2026-05-11
0 浏览
中国品牌市占率达75%,4月我国汽车销量约252.6万辆,新能源汽车出口贡献度近五成
2026-05-11
0 浏览
4月汽车出口增长51% 国内零售下跌超20%
2026-05-11
0 浏览
4月全国新能源汽车渗透率历史首次突破60%,燃油车零售同比暴跌37%
2026-05-11
0 浏览
港股复盘:强势翻红 芯片概念股冲高回落 短期风险需警惕
2026-05-11
0 浏览
申昊科技拟设具身智能子公司 加码人形机器人业务
2026-05-11
0 浏览


