

TAG:图像编辑

谷歌发布全新Google Pics应用,AI助力图像设计与编辑
谷歌在2026年I/O开发者大会上发布了全新的Google Pics应用,这是一款AI驱动的图像生成与设计工具。用户可以通过文字或语音指令快速生成活动邀请函、海报等视觉内容,并支持灵活的局部编辑,如修改图片元素和文字,提高设计效率。应用以网页形式上线,未来计划推出移动应用并整合到Workspace中,为用户提供更便捷的设计体验。

Adobe Photoshop 引入 AI 旋转对象功能,2D 素材可快速生成 3D 效果
Adobe 最新更新为 Photoshop 和 Lightroom 带来多项 AI 能力升级,其中“旋转对象”可让 2D 素材实现类 3D 视角调整,并自动匹配光影与环境。与此同时,图层清理、自然语言搜索和性能提速等功能,也显著提升了设计与摄影工作流效率。
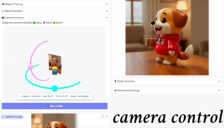
从平面修图到空间重塑:京东开源图像模型JoyAI-Image-Edit重新定义AI编辑
京东探索研究院正式开源JoyAI-Image-Edit图像模型,引领AI修图迈向“空间智能”新阶段。该模型通过深度建模三维空间,实现了对相机视角、物体位移及缩放的精准控制,并全面兼容15类通用编辑需求。其出色的几何一致性与物理规律理解力,为电商生产、创意设计及具身智能等领域提供了强大的底层技术支撑。

告别AI标准脸!阿里Wan2.7-Image发布:能写A4纸论文,还能像素级“捏脸”
阿里发布Wan2.7-Image图像生成与编辑大模型,突破传统AI生图局限,实现个性化虚拟角色捏脸、调色盘功能及印刷级文字渲染。支持交互式编辑和多主体一致性,广泛应用于短剧制作、电商广告等领域。
腾讯混元图像3.0开源,800亿参数引领AI创作新纪元
腾讯混元团队正式开源全球最强开源图生图模型——混元图像3.0,拥有800亿参数,采用混合专家架构,在LMArena榜单中位列第一梯队。模型通过‘先思考,后编辑’的核心技术,深度融合文本与视觉理解,支持增删改、风格变换、老照片修复等多种编辑功能,适用于从普通用户到专业设计师的广泛场景。

通义千问发布Qwen-Image-Layered模型 支持图片分层编辑
通义千问团队发布创新图像生成模型Qwen-Image-Layered,通过‘图层拆解’技术将静态图片分解为语义独立的RGBA图层,实现精准的‘指哪改哪’编辑。该模型解决了传统AI编辑中全局破坏一致性和局部边界模糊的痛点,支持重新着色、物体替换、文字修改等操作,并允许可变数量图层分解与无限层级细化,为用户提供直观、鲁棒的图片编辑能力。


美团开源6B参数图像生成模型LongCat-Image,中文图文生成与编辑达SOTA
美团LongCat团队开源6B参数图像生成模型LongCat-Image,在文生图和图像编辑任务中达到开源SOTA水平。模型特别优化中文文字生成,支持复杂汉字渲染,适用于海报设计等场景。通过课程学习和主观评估确保高质量输出,用户可通过Hugging Face和GitHub访问体验。
Lovart AI上线“元素拆分”功能,一张海报秒变可编辑PSD
Lovart AI推出革命性'元素拆分'功能,可将成品海报智能分解为可独立编辑的文字层、主体层和背景层,支持直接修改内容、字体和排版。该功能大幅降低设计门槛,让非专业用户也能轻松编辑图像,仅需5个信用点即可无限次微调,真正实现从'生成'到'编辑'的AI设计范式跃迁。

中文图像编辑迎来新王!UniWorld-V2发布,框选即改、中文字体精准渲染,性能碾压GPT-Image与Gemini
UniWorld-V2是由兔展智能与北京大学联合推出的新一代图像编辑模型,基于创新的UniWorld-R1强化学习框架,在图像编辑领域实现重大突破。该模型支持框选即改操作,能够精准理解中文指令并渲染复杂中文字体,在GEdit-Bench和ImgEdit测试中性能显著超越GPT-Image与Gemini等知名模型,为多模态图像编辑技术带来新的可能性。







